Chapter 5 Kernel Methods and Manifold Learning
5.1 Kernels and the Kernel Trick
The techniques considered in the previous chapter (PCA, NMF, SVD, and classical Scaling) are ill suited to identify nonlinear structure and dependence in data. If we wish to most efficiently reduce dimensions without loss of information, we will need techniques which incorporate nonlinear structure. One can expand a data matrix by including specific nonlinear relationships then apply PCA or SVD but there are numerous problems with this approach. In particular, which relationships does one choose to include? Even including simple quadratic or cubic terms (features) can result in a data matrix with a massive increase in the number of columns. Even when the original dimensionality of the data is moderate, the including of polynomial terms can quickly result in a data matrix of nonlinear features with an untenable number of columns which can make application of the linear methods we have discussed much more computationally demanding to implement.
Kernels are a important class of functions which can be used to kernelize the methods we have discussed before. In theory, these kernelized versions of the linear methods we have discussed can identify and use nonlinear structure for better dimensionality reduction while circumventing the issue of higher dimensional featurized data. This approach follows from an application of the so called ’kernel trick` which we now discuss.
Briefly, a kernel is a function \[k:\mathbb{R}^d\times \mathbb{R}^d \to \mathbb{R}\] which has an associated feature space, \(\mathcal{H}\) and (implicity defined, possibly nonlinear) feature mapping \(\varphi:\mathcal{R}^d \to \mathcal{H}\) such that inner products in the feature space, denoted \(\langle \varphi(\vec{x}), \varphi(\vec{y})\rangle_{\mathcal{H}}\) can be obtained through an evaluation of the kernel, namely \[\begin{equation} k(\vec{x},\vec{y}) = \langle \varphi(\vec{x}), \varphi(\vec{y})\rangle_{\mathcal{H}} \end{equation}\]
Any method which can be expressed involving inner products can be kernelized by replacing terms of the form \(\vec{x}^T_i\vec{x}_j\) with the quantity \(k(\vec{x}_i,\vec{x}_j)\). Thus, we are replacing inner products of our original \(d\)-dimensional data with inner products in the associated feature space \(\mathcal{H}\). Importantly, if we only need inner products, we never need to explicitly compute the feature map \(\varphi\) for any of our data! At first glance this connection may seem minor, but by using kernels we can turn many linear techniques into nonlinear methods including PCA, SVD, support vector machines, linear regression, and many others.
There are some limits though. Not every choice of \(k\) has an associated feature space. A function is only a kernel if it satisfies Mercer’s Condition.
Theorem 5.1 (Mercer's Condition) A function \[k:\mathbb{R}^d\times \mathbb{R}^d \to \mathbb{R}\] has a an associated feature space \(\mathcal{H}\) and feature mapping \(\varphi:\mathbb{R}^d \to \mathcal{H}\) such that \[k(\vec{x},\vec{y}) = \langle \varphi(\vec{x}), \varphi(\vec{y})\rangle_{\mathcal{H}}, \qquad \forall \vec{x},\vec{y}\in\mathbb{R}^d\] if and only if for any \(N \in \{1,2,\dots\}\) and \(\vec{x}_1,\dots,\vec{x}_N\in\mathbb{R}^d\) the kernel matrix \({\bf K}\in \mathbb{R}^{N}\) with entries \({\bf K}_{ij} = k(\vec{x}_i,\vec{x}_j)\) is positive semidefinite. Equivalently, it must be the case that \[\int_{\mathbb{R}^d}\int_{\mathbb{R}^d} g(\vec{x})g(\vec{y}) k(\vec{x},\vec{y}) d\vec{x}d\vec{y} \ge 0\] whenever \(\int_{\mathbb{R}^2}[g(\vec{x})]d\vec{x}<\infty.\)
We will only consider symmetric functions such that \(k(\vec{x},\vec{y}) = k(\vec{y},\vec{x})\) for all \(\vec{x},\vec{y}\in\mathbb{R}^d\). It may not be immediately obvious if a symmetric function satisfies Mercer’s condition, but there are many known examples. A few are shown in the following table.
| Name | Equation | Tuning Parameters |
|---|---|---|
| Radial Basis Function | \(k(\vec{x},\vec{y} = \exp\left(-\sigma\|\vec{x}-\vec{y}\|^2\right)\) | Scale \(\sigma >0\) |
| Laplace | \(k(\vec{x},\vec{y} = \exp\left(-\sigma\|\vec{x}-\vec{y}\|\right)\) | Scale \(\sigma >0\) |
| Polynomial | \(k(\vec{x},\vec{y}) = (c+ \vec{x}^T\vec{y})^d\) | Offset \(c >0\), Degree \(d \in \mathbb{N}\) |
The radial basis function (rbf) is the most commonly used kernel and has an associated feature space \(\mathcal{H}\) which is infinite dimensional! The associated feature map \(\varphi\) for the rbf kernel is \[\varphi(\vec{x}) = e^{-\sigma\|\vec{x}\|^2}\left(a_{\ell_0}^{(0)}, a_{1}^{(1)},\dots,a_{\ell_1}^{(1)}, a_{1}^{(2)},\dots, a_{\ell_2}^{(2)},\dots \right)\] where \(\ell_j = \binom{d+j-1}{j}\) and \(a_\ell^{(j)} = \frac{(2\sigma)^{j/2}x_1^{\eta_1}\dots x^{\eta_d}}{\sqrt{\eta_1!\dots\eta_d!}}\) when \(\eta_1+\dots+\eta_d = j.\) The preceding expression is quite cumbersome, but there is one important point to emphasize. Every possible polynomial combination of the coordinates of \(\vec{x}\) appears in some coordinate of \(\varphi(\vec{x})\) (though higher order terms are shrunk by the factorial factors in the denominator of \(a_\ell^{(j)}\)). Thus, the rbf kernel is associated with a very expressive feature space which makes it a potent but dangerous choice since risks overfitting. To explore these details more, let’s discuss one very important application of kernels in unsupervised learning.
5.2 Kernel PCA
Suppose we have a kernel \(k\) and associated feature map \(\varphi\). In kernel PCA, we want to apply to PCA to the featurized data \(\varphi(\vec{x}_1),\dots,\varphi(\vec{x}_N)\) rather than the original data. The idea is that by studying the featurized data, we can identify additional nonlinear structure in the features that provides a better lower-dimensional representation of the data. We have discussed three approaches to computing PC scores to data: (i) diagonalization of the sample covariance, (ii) applying SVD to the centered data, and (iii) using the duality of PCA and classical scaling.
For the rbf kernel and its infinite dimensional feature map, approaches (i) and (ii) are impossible. Why? The centered data matrix of features \[{\bf H}\tilde{\bf X} = {\bf H}\begin{bmatrix} \varphi(\vec{x}_1)^T \\ \vdots \\ \varphi(\vec{x}_N)^T\end{bmatrix} =\begin{bmatrix} \varphi(\vec{x}_1)^T-\bar{\varphi}^T \\ \vdots \\ \varphi(\vec{x}_N)^T-\bar{\varphi}^T\end{bmatrix} \] has a infinite number of columns so that we cannot compute its SVD. In the above expression, \(\bar{\varphi} = \frac{1}{N} \sum_{i=1}^N \varphi(\vec{x}_i)\) is the mean for the feature vectors. The associated sample covariance matrix \[{\bf \Sigma}_F = \frac{1}{N} \tilde{\bf X}{\bf H}\tilde{\bf X } = \frac{1}{N} \sum_{i=1}^N \left(\varphi(\vec{x}_i) - \bar{\varphi}\right)\left(\varphi(\vec{x}_i) - \bar{\varphi}\right)^T\] will have an infinite number of rows and columns so we cannot hope to diagonalize it either.
Fortunately, the third option, using duality of classical scaling and PC, provides a workaround. Observe that the inner product matrix of the centered feature data \({\bf H}\tilde{\bf X} ({\bf H}\tilde{\bf X})^T\) can be written in terms of the kernel since \[{\bf H}\tilde{\bf X} ({\bf H}\tilde{\bf X})^T = {\bf H} \begin{bmatrix} \varphi(\vec{x}_1)^T \\ \vdots \\ \varphi(\vec{x}_N)^T\end{bmatrix} \begin{bmatrix} \varphi(\vec{x}_1) & \dots & \varphi(\vec{x}_N)\end{bmatrix} {\bf H} = {\bf H K H}\] where \({\bf K}\) has the inner products in the feature space which we can calculate using the kernel function \[{\bf K}_{ij} = \varphi(\vec{x}_i)^T\varphi(\vec{x}_j) = k(\vec{x}_i,\vec{x}_j).\]
Since \(k\) is a symmetric kernel, it follows that \({\bf K}\) is positive semidefinite. Using this property, one can argue that \({\bf HKH}\) will also be positive semidefinite. We can use the eigendecomposition of the doubly centered kernel to compute the kernel principal component scores. Specifically, if \({\bf HKH}\) rank \(r\) with eigenvalues \(\lambda_1\ge \dots \ge \lambda_r >0\) and corresponding eigenvalues \(\vec{u}_1,\dots,\vec{u}_r \in \mathbb{R}^N\), then \({\bf HKH}\) factorizes as \[{\bf HKH} = \underbrace{\begin{bmatrix}\vec{u}_1 & \dots &\vec{u}_r\end{bmatrix} \begin{bmatrix} \lambda_1^{1/2} &0 &0 \\ 0& \ddots & 0 \\ 0 &0 & \lambda_r^{1/2} \end{bmatrix}}_{{\bf U\Lambda}^{1/2}} \left({\bf U\Lambda}^{1/2}\right)^T. \]
The rows of the matrix \({\bf U\Lambda}^{1/2}\) are almost the kernel PC scores. The only issue is an additional the identity \[{\bf HKH} = ({\bf H}\tilde{\bf X})({\bf H}\tilde{\bf X})^T\] is missing the factor of \(1/N\) appearing in the covariance calculation. Accounting for this, the first \(r\) non-zero kernel PC scores are the rows of the matrix \[\frac{1}{\sqrt{N}} {\bf U\Lambda}^{1/2}\] and the corresponding nonzero PC variances are \(\lambda_1/N,\dots,\lambda_r/N.\)
Notably, at no point do we compute the PC loadings! However, similar to standard PCA, we use the scores for dimension reduction and the PC variances for choosing a dimension. Without the loadings, we cannot recompute the original data. Below, we show an application of kernel PCA to the helix and demonstrate its ability to identify the one-dimensional structure of the helix and its sensitivity to kernel selection and tuning.
Example 5.1 (Kernel PCA applied to the Helix) First, we show the kPCA variances for three different kernels and tuning parameters. The data are regularly spaced points along the helix.
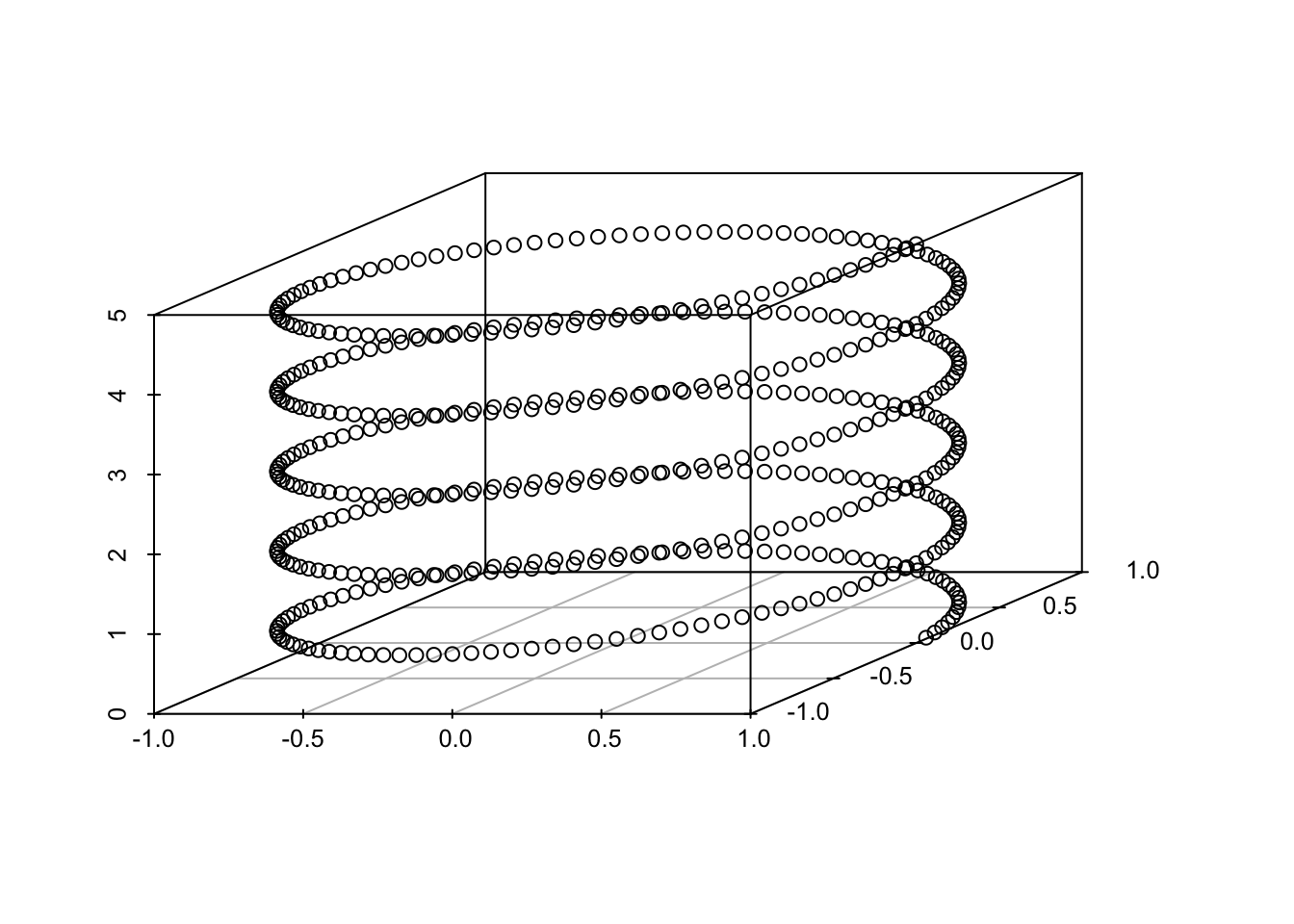
From these graphs, one would infer very different lower dimensional choices depending on the kernel and parameters. The polynomial kernel provides the most robust estimate of the one-dimensional nature of the data.
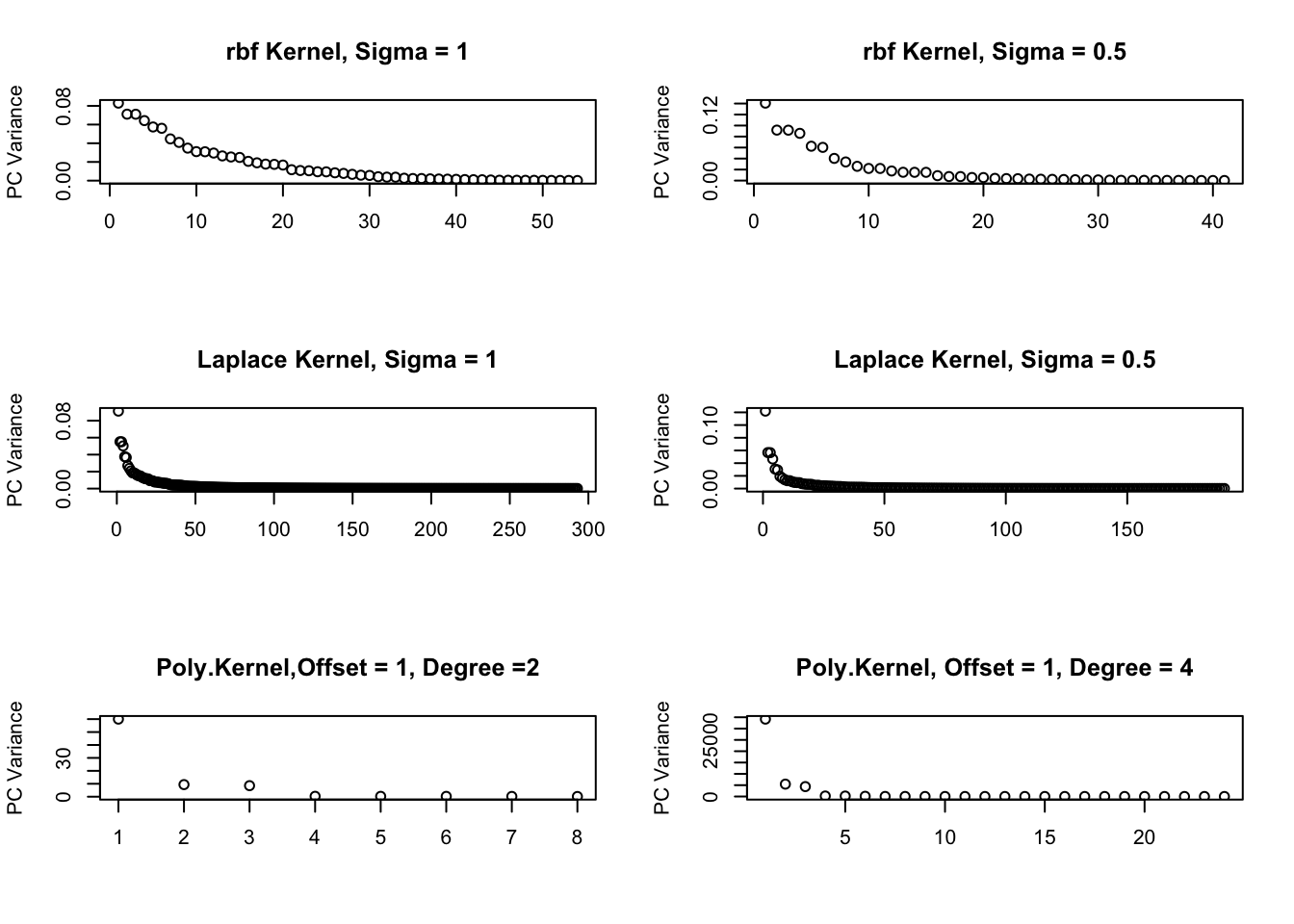
Figure 5.1: kPCA Variances for different Kernels
Below, we show the recovered one-dimensional coordinates for the polynomial kernel with offset 1 and degree 4 shown below, which is good, but do not quite reflect the equal spaced nature of the points.
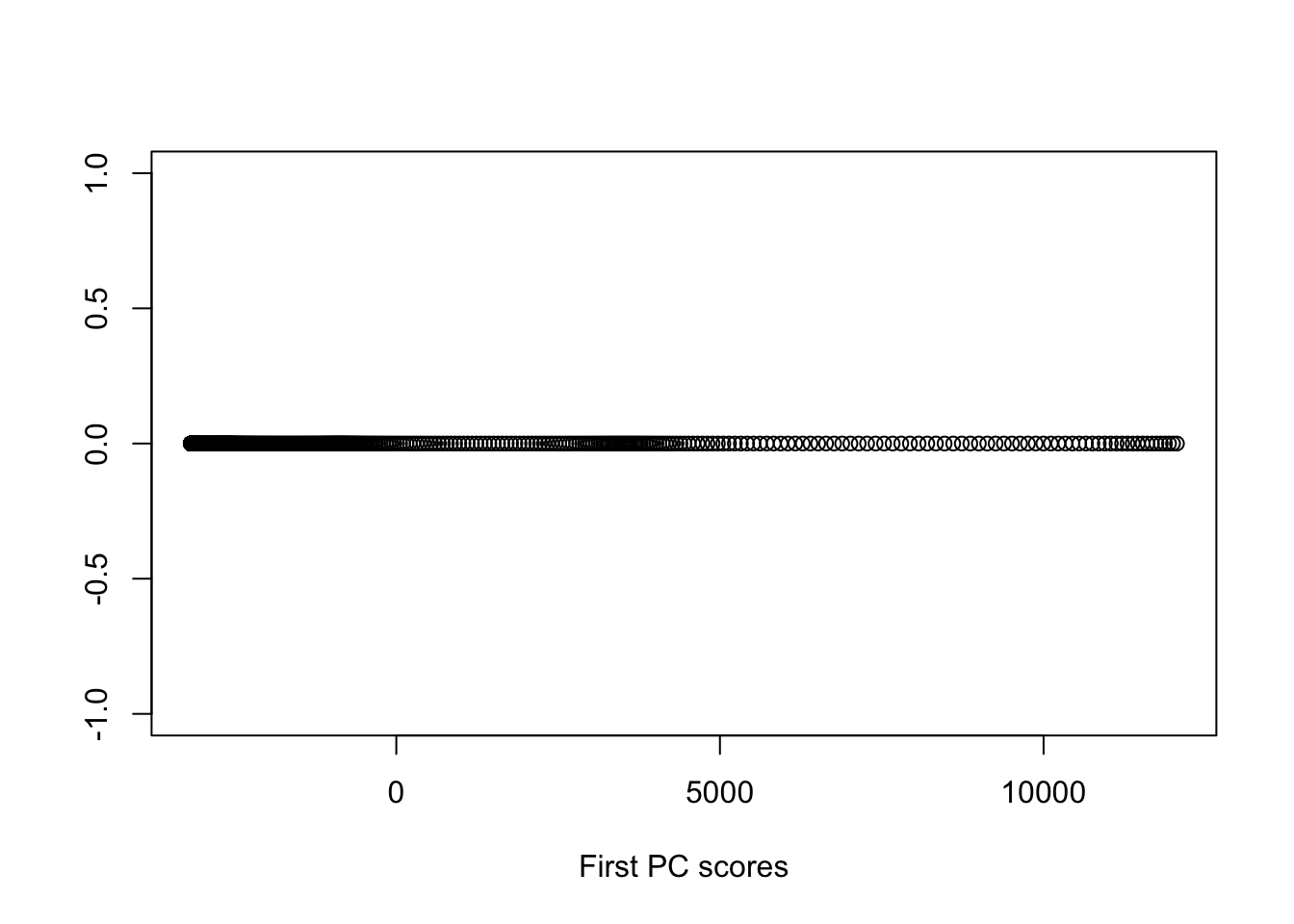
As the preceding example demonstrates, kernel PCA can identify nonlinear structure, but is quite sensitive to kernel selection and tuning. More advanced implementations make use of cross-validation to aid in the selection and tuning of the kernel [22].
5.3 Brief primer on manifolds and differential geometry
In the preceding section, we focused our attention on linear manifolds and saw cases where this structure was insufficient. Using kernel PCA, we tried to find a workaround by first (implicity) mapping our data to a higher dimensional feature space then approximating results with linear subspaces (of feature space). We now turn to a family of methods that take a more direct approach, assuming the data live on or near a manifold – the manifold hypothesis introduced in Section 3.1 – rather than relying on a fixed kernel. While our data may exhibit some low-dimensional structure, there is no practical reason to expect such behavior to be inherently linear. In the remaining sections of this chapter, we will explore methods which consider nonlinear structure directly. Such methods are referred to as nonlinear dimension reduction or manifold learning. Critical to this discussion is the notion of a manifold.
Definition 5.1 (Informal Definition of a Manifold) A manifold is a (topological) space which locally resembles Euclidean space. Each point on a \(t\)-dimensional manifold has a neighborhood that can be mapped continuously to \(\mathbb{R}^t\). We call \(t\) the intrinsic dimension of the manifold.
We’ll return to mathematical details shortly, but let’s stick with intuition for now. If you were to stand at any point on a \(k\)-dimensional manifold, the portion of the manifold closest to you look just like a \(k\)-dimensional hyperplane – though you might need to be extremely near-sighted for this to be true. The canonical example is the surface of the Earth. If we take all points on the surface of the Earth, they form a sphere in \(\mathbb{R}^3\). However, if we focus on the area around any point it looks like a portion of the two-dimensional plane. In fact, we can represent any point on the surface of the Earth in terms of two numbers, latitude and longitude. In the language of manifolds, we can say the surface of the Earth is a manifold with intrinsic dimension two which has been embedded in \(\mathbb{R}^3\). Here are a few more concrete examples.
Example 5.2 (Examples of Manifolds) Many familiar geometric objects are manifolds such as lines, planes, and spheres. For example, Let \(\vec{w}_1,\dots,\vec{w}_k\in\mathbb{R}^d\) be a set of linearly independent vectors. Then \(\text{span}(\vec{w}_1,\dots,\vec{w}_k)\) is a \(k\)-dimensional manifold in \(\mathbb{R}^d.\) When \(k=1\), the span is a line; for \(k>1\) the span is a hyperplane. The sphere unit sphere \(\{\vec{x}\in\mathbb{R}^d:\,\|\vec{x}\|=1\}\) is a \(d-1\) dimensional manifold. For example, when \(d=3\) manifold resembles the surface of the earth which locally looks like a portion of the 2-dimensional plane. The Swiss roll from Example 3.1 is a two-dimensional manifold in \(\mathbb{R}^3\).
In short manifold as a nice smooth, curved surface. There are several reasons why a subset may not be a manifold. The most straightforward examples are cases where the manifold as a self intersection or a sharp point.
Example 5.3 (Non-manifold) Consider a figure eight curve. At the midpoint where the upper and lower circle meet, there is not neighborhood that resembles Euclidean space so the surface is not a manifold.
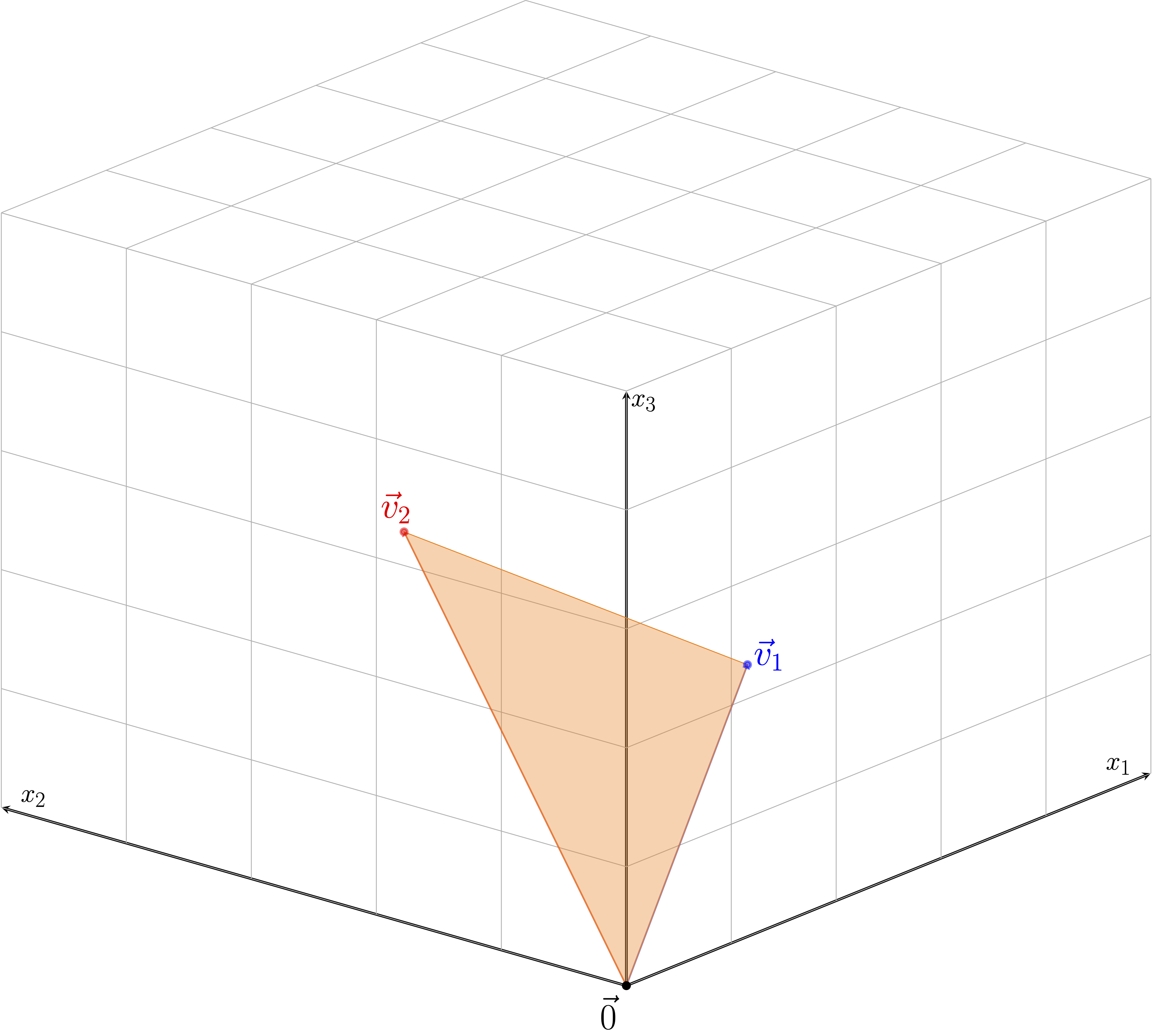
For a second example, take any two vectors \(\vec{h}_1\) and \(\vec{h}_2\) and consider there convex hull, that is \(\{a\vec{h}_1+b\vec{h}_2: a,b > 0, a+b\le 1\}\) such the orange triangle in the figure below. At the three vertices of the orange triangle, there is no local neighbor that looks flat. However, if we were to exclude the edges and vertices of the triangle, the subset would be a two-dimensional manifold; thus, \(\{a\vec{h}_1+b\vec{h}_2: a,b > 0, a+b< 1\}\) is a manifold while \(\{a\vec{h}_1+b\vec{h}_2: a,b > 0, a+b\le 1\}\) is not.
5.3.1 Charts, atlases, tangent spaces and approximating tangent planes
Hereafter, we will focus on manifolds which are a subset of \(\mathbb{R}^d\), which are often referred to as submanifolds. Differential geometry can be made far more abstract, but that is unnecessary for the discussion here. After all, we’re dealing with finite dimensional data so any nonlinear surface containing our data must be a submanifold of \(\mathbb{R}^d\)!
Now, some mathematical foundation. Let \(\mathcal{M}\) be a manifold in \(\mathbb{R}^d\) with intrinsic dimension \(t<d\). For every point \(\vec{x}\in\mathcal{M}\), there is a neighborhood \(U_x\subset \mathcal{M}\) containing \(\vec{x}\) and a function \(\phi_x: U_x \to \phi_x(U_x) \subset \mathbb{R}^t\) which is continuous, bijective, and has continuous inverse (a homeomorphism if you like greek). The pair \((U_x,\phi_x)\) is called a chart and behaves much like a map of the area around \(\vec{x}\). There are many choices for \(\phi_x\), but we can always choose one which maps \(\vec{x}\in\mathbb{R}^d\) to the origin in \(\mathbb{R}^t\). For vectors \(\vec{z}\in U_x\), we call \(\phi_x(\vec{z})\in\mathbb{R}^t\) the local coordinates of \(\vec{z}.\)
Example 5.4 (Charts and Manifold Maps) Let’s revisit the Swiss roll example (Example 3.1) where \(A = (\pi/2,9\pi/2)\times (0,15)\). We defined the map \(\Psi:A\to \mathbb{R}^3\) as follows \[\Psi(\vec{z}) = \Psi(z_1,z_2) = \begin{bmatrix} z_1\sin(z_1) \\ z_1\cos(z_1) \\ z_2 \end{bmatrix}.\] For other manifolds, we may need multiple charts to cover the manifold, but we only need one chart the swiss roll (or any manifold defined through a homeomorphic manifold map). Let the neighborhood be the entire manifold, i.e. \(U = \mathcal{M}\) Given \(\vec{x}=(x_1,x_2,x_3)^T\), let \(\phi(\vec{x}) = (\sqrt(x_1^2+x_2^2),x_3)^T.\) This chart essentially unrolls the swiss roll and turns it back into a rectangle in \(\mathbb{R}^2\) so that the local coordinates are the original coordinates!
If we take a collection of charts \(\{U_x,\phi_x\}_{x \in \mathcal{I}}\) such that \(\cup_{x\in\mathcal{I}}U_i = \mathcal{M}\), we have at atlas for the manifold. Here \(\mathcal{I}\) is a subset of \(\mathcal{M}\) which could be countable or finite. With a chart, we can consider doing differential calculus on the manifold. In particular, if \(f:\mathcal{M}\to\mathbb{R}\), then for a chart \((U_x,\phi_x)\), the function \(f\circ \phi_x^{-1}\) is a map from a subset of \(\mathbb{R}^t\) (namely \(\phi_x(U)\)) to \(\mathbb{R}\) so we might hope that we could apply the typical rules of calculus. However, if we have two charts \((U_y,\phi_y)\) and \((U_x,\phi_x)\) which overlap – \((U_x\cap U_y) \ne \emptyset\) – then derivatives \(f\circ \phi_x^{-1}\) and \(f\circ \phi_y^{-1}\) should agree on \(U_x\cap U_y\). More succinctly, the rules of calculus should remain consistent across charts!
Definition 5.2 (Differentiable Manifolds) An atlas \(\{U_x,\phi_x\}_{x\in\mathcal{M}}\) is differentiable if the transition maps \(\phi_x \circ \phi_y^{-1}: \phi_y(U_y) \to \mathbb{R}^t\) are differentiable functions. Recall \(\phi_y(U_y)\subset\mathbb{R}^t\) so differentiable in this case follows the traditional Euclidean definition from calculus.
With some additional properties and manifold with a differential atlas is a differentiable manifold allowing us to compute derivatives of function from the manifold to the reals. We’ll revisit this detail again when discussion Hessian Local Linear Embeddings. For now, let’s assume we have a differentiable manifold with intrinsic dimension \(t\). To every point on the manifold, we can attach a \(t\)-dimensional tangent space. There are several methods for defining the tangent space, but the most straightforward involves the case where we have a manifold map. We’ll restrict our attention to this case.
Definition 5.3 (Tangent Space) Let \(A\subset\mathbb{R}^t\) and let \(\Psi:A\to \mathcal{M}\subset \mathbb{R}^d\). Furthermore, suppose \(\Psi\) has coordinate functions \(\Psi_1,\dots,\Psi_d: A \to \mathbb{R}\) such that for \(\vec{y}=(y_1,\dots,y_t)^T\in A\), \(\Psi(\vec{y}) = (\Psi_1(\vec{y}),\dots,\Psi_d(\vec{y}))^T.\) The Jacobian of \(\Psi\), denoted \({\bf J}_{\Psi}\) is the \(d\times t\) dimensional matrix of partial derivative such that \[({\bf J}_{\Psi})_{ij} = \frac{\partial \Psi_i}{\partial y_j}.\] The tangent space of the manifold \(\mathcal{M}\) at the point \(\vec{p}=\Psi(\vec{y})\), denoted \(T_p(\mathcal{M})\) is the column span of \(({\bf J}_{\Psi})\) evaluated at \(\vec{y}\).
The manifold locally resembles \(\mathbb{R}^t\) so the tangent space should also be \(t\)-dimensional. As such, we’ll require \({\bf J}_{\Psi}\) to be a full rank matrix (with rank \(t\) since \(t < d\)) for every \(\vec{y}\in A\). Importantly, the tangent space is a linear subspace meaning it passes through the origin. This should not be confused with tangent plane to the manifold which we now define.
Definition 5.4 (Tangent Plane) Suppose a manifold \(\mathcal{M}\) has tangent space \(T_p(\mathcal{M})\). Then the approximating tangent plane to the manifold is the affine subspace obtained by translations, namely \(\{\vec{x}\in\mathbb{R}^d: \vec{x}-\vec{p} \in T_p(\mathcal{M})\}.\)
Let’s return to the swiss roll to make these details explicit.
Example 5.5 (Jacobians and Tangent Space for the Swiss Roll) The Jacobian of the swiss roll map is \[{\bf J}_{\Psi} = \begin{bmatrix} z_1\cos(z_1) + \sin(z_1) & 0 \\ -z_1\sin(z_1) + \cos(z_1) & 0 \\ 0 & 1 \end{bmatrix}.\] At the point \(\Psi(3\pi/2,5)=(-3\pi/2,0,5)^T\) the Jacobian is \[{\bf J}_{\Psi}\mid_{(3\pi/2,5)^T} = \begin{bmatrix} -1 & 0 \\ -3\pi/2 & 0 \\ 0 & 1 \end{bmatrix}\] so \[T_{(3\pi/2,0,5)^T}(\mathcal{M}) = \text{span}\{(1,3\pi/2,0)^T, (0,0,1)^T\}.\] We can view the associated approximating tangent plane (translucent blue) at the point \((3\pi/2,0,5)^T\) (in red).